The current generation of department PACS was designed over ten years ago. That statement also applies to the workflow and worklist components of the PACS solution as well as the system architecture. The workflow application was designed to assemble images for interpretation by a single physician group working in a single imaging department, working with a single department PACS. The concept of prioritization was placing a STAT icon next to a study ordered by an Emergency Room physician, and perhaps applying a background color to that line item in the list. Today, even mid-sized healthcare organizations are commonly made up of several amalgamated radiology groups (some owned, some affiliated). They have multiple EMRs and PACS solutions. These organizations have to manage complex cross-site credentialing issues while trying to deliver a common standard of care across the new integrated enterprise. In addition to this, the organization has to hold each physician group to similar performance goals. The worklist of each individual physician absolutely has to consider such input as: physician availability (schedule, locations, etc.), turn around time, physician RVU loading, sub-specialty reading, credentialing, critical results reporting, and peer review. None of the current generation department PACS have a workflow application that addresses today’s issues much less future issues we can barely imagine. A new generation of workflow application that is applicable to the enterprise is clearly needed.
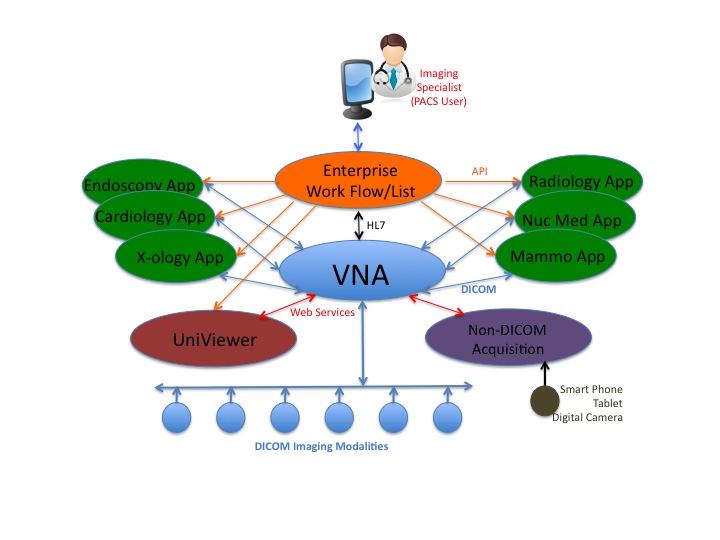
Enterprise Workflow Launching Most Suitable Display Application as determined by Study Descriptors
There have been improvements over the last ten years in the features and functions of the diagnostic display application, and yet most imaging departments have had to augment their core PACS application with a number of third-party specialty display applications. The physicians have to work through a pull down list of these applications in order to find the one that is the most suitable to use in the interpretation of the study they have pulled off their worklist. Similar to the way the enterprise workflow solution needs to provide a federated view of available studies to read, the enterprise workflow needs to provide federated access to all the available diagnostic display resources within a site or across a multi-site enterprise.
An enterprise workflow/worklist application is also one of the key components of the next-generation PACS. The PACS 3.0 configuration that I describe in the white paper recently published as a three-part series on AuntMinnie.com. is based on a Vendor Neutral Archive. The various diagnostic display applications that might be used in one or more imaging departments to interpret the images are simply plug-ins to the VNA. As the brain of the PACS 3.0 configuration, the enterprise workflow/worklist application is the entry point of all of the interpreting physicians in all of the imaging departments. The individual physician worklist presents the highly specific list of studies to be read and the underlying workflow launches the most appropriate diagnostic display application based on the pre-defined choices of the physician and the specific type of study selected from the list.
The new diagnostic imaging paradigm, PACS 3.0, is relevant to more than the radiology department. Medical imaging has always been an enterprise operation. Radiology and cardiology are the most obvious medical imaging operations, but many more clinically relevant medical images are generated in other departments. The images captured during an endoscopic procedure do in fact comprise an imaging study that is interpreted. Images captured during an office visit (dermatology) or throughout the course of treatment (wound care) are perhaps not considered an imaging study, but they nonetheless are clinically significant and should be retained as part of the patient’s medical image record.
The PACS 3.0 paradigm should be extended to all of the departments in the enterprise that utilize imaging. The endoscopy study can be ingested by the VNA and the enterprise workflow application can create the worklist for the Endoscopist, and that workflow application would most likely launch a basic clinical display application to review the study, whether the images are DICOM or JPEG.
A similar scenario can be applied to each of the other imaging operations, whether those images are DICOM or non-DICOM. The later may require a front-end application to create the study from a collection of individual images and associate the proper patient and study metadata to the study, but the VNA is the data repository and the enterprise workflow application is the entry-point for the physicians responsible for interpreting the images.
Now is the time for a single workflow/worklist application that can be used across the entire enterprise. Not only does a single workflow application simplify physician access, a single workflow application consolidates software applications, simplifies IT support, and makes economic sense.
The white paper I recently wrote on Enterprise Workflow would be useful in your strategic planning. The paper describes a key attribute of Enterprise Workflow being [1] its ability to auto-route the new image study and its relevant priors to the server hosting the display application that is most suited to the interpretation of the study, and [2] its ability to launch that display application in patient context when the study is selected from the worklist. This functionality is based on the workflow application’s ability to recognize and use the study descriptors and the physician reading preferences to determine the most suited display application. In this sense, the enterprise workflow application is really the brain of the enterprise medical image management solution.